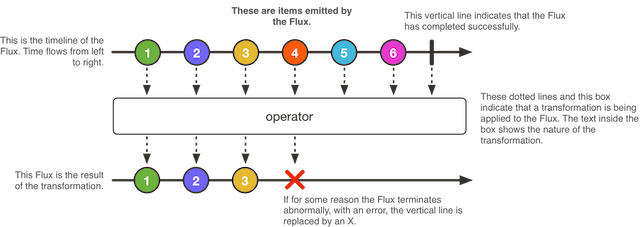
Zeebe Docs翻译:2.4 分区
温馨提示:
本文最后更新于 2019年10月08日,已超过 2,026 天没有更新。若文章内的图片失效(无法正常加载),请留言反馈或直接联系我。
注意:如果您以前使用过Apache Kafka系统,那么您对本页面上介绍的概念将非常熟悉。
在Zeebe,所有数据都被组织到分区。一个分区是工作流相关事件的持续流。在代理群集中,分区分布在节点之间,因此可以将其视为碎片。引导Zeebe代理时,可以配置所需的分区数量。
使用范例
无论何时部署工作流,都将其部署到第一个分区。然后将工作流分发到所有分区。在所有分区上,此工作流程将接收相同的密钥和版本,以便可以一致地对其进行标识。
启动工作流实例时,客户端库会将请求路由到将在其中发布工作流实例的一个分区。工作流实例的所有后续处理将在该分区中进行。
可扩展性
使用分区来扩展您的工作流程处理。分区动态地分布在Zeebe群集中,并且每个分区一次都有一个领先的代理。该领导者接受请求并对该分区执行事件处理。让我们假设您要在五台计算机上分配工作流处理负载。您可以通过引导五个分区来实现。
分区数据布局
分区是一个持久的仅追加事件流。最初,分区是空的。当插入第一个条目时,它将取代第一个条目。当第二个条目进入并插入时,它将代替第二个条目,依此类推。每个条目在分区中都有一个唯一标识它的位置。

复写
为了实现容错,将分区中的数据从分区的负责人复制到其跟随者。跟随者是其他Zeebe Broker节点,它们维护分区的副本而不执行事件处理。
推荐建议
选择分区的数量取决于用例,工作量和集群设置。以下是一些经验法则:
- 为了进行测试和早期开发,请从单个分区开始。请注意,Zeebe的工作流程处理已针对效率进行了高度优化,因此单个分区已经可以处理高事件负载。
- 使用单个Zeebe Broker,单个分区就足够了。但是,如果节点具有许多核心,并且将代理配置为使用它们,则更多分区可以增加总吞吐量(每个分区2个线程)。
- 根据数据做出决定。模拟预期的工作负载,测量并比较不同分区设置的性能。
正文到此结束
- 本文标签: 其他
- 本文链接: https://www.v8en.com/article/187
- 版权声明: 本文由SIMON原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权