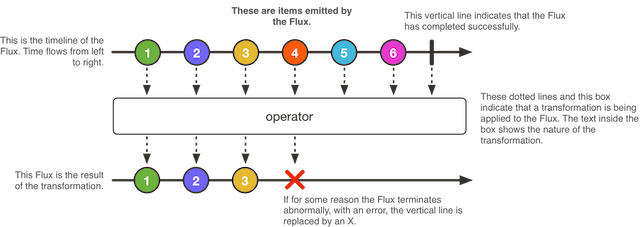
How to take control over the execution of Mono and Flux ?
Reactor is a Java library for creating reactive non-blocking applications on the JVM based on the Reactive Streams Specification.
This article is the forth of a series which goal is to guide you through the process of creating, manipulating and managing the execution of the Reactive Streams that offer Reactor through the Mono and Flux classes.
In the first three articles we covered how to create Mono and Flux, how to apply transformations to the data they hold and how they behave.
In this forth article, we will see how to take control over the way Flux and Mono are executed, either sequentially or in parallel. And also how to configure on which thread pool to run all the operations, or only one operation.
Schedulers
In computing, scheduling is the method by which work specified by some means is assigned to resources that complete the work. The work may be virtual computation elements such as threads, processes or data flows, which are in turn scheduled onto hardware resources such as processors, network links or expansion cards.
— Wikipedia
Reactor uses schedulers to manage on which thread pool the computing of your stream should be processed. The library embed four already configured schedulers that you can use to control the execution of your streams.
The 4 schedulers offered by Reactor are :
- single: a one worker thread scheduler
- immediate: a scheduler that computes the stream in the thread where the call to the method configuring it is done.
- parallel: a scheduler that has as many workers as your CPU has cores (or threads if supporting hyper threading). The method it uses to get the amount of workers to use is
Runtime.getRuntime().availableProcessors() - elastic: a scheduler that dynamically creates threads when needed, with no up limit. A thread is released after 60 non-working seconds.
These 4 schedulers are accessible through the Schedulers class via static methods.
More options are available for the schedulers. If you want to know more about this, I recommand you dive into the documentation.
How to configure a Mono or Flux’s scheduler
Mono and Flux have two methods to configure the scheduler to use. They are subscribeOn(Scheduler scheduler) and publishOn(Scheduler scheduler) . These two methods are pretty different.
SubscribeOn
subscribeOn(...) sets the scheduler for all the operations of your stream. It doesn’t matter when you call the method. So the below two codes do exactly the same, they are fully executed on a single scheduler:
Mono.just("1").
map(Integer::valueOf).
subscribeOn(Schedulers.single()).
subscribe(System.out::println)Mono.just("1").
subscribeOn(Schedulers.single()).
map(Integer::valueOf).
subscribe(System.out::println)
A word about a counter intuitive thing with subscribeOn(...) . If the method get called multiple times on a stream, only the first one will be taken in account. So, the below code will run on the single scheduler and not the elastic one. This is important to know when working with streams that are modified along several methods or with libraries that return instances of Mono andFlux .
Mono.just(“1”).
subscribeOn(Schedulers.single()).
map(Integer::valueOf).
subscribeOn(Schedulers.elastic()).
subscribe(System.out::println)PublishOn
publishOn(...) sets the scheduler for all the operations that follow this method call. It will override the scheduler set with the subscribeOn method.
Mono.just(“1”).
subscribeOn(Schedulers.single()).
map(Integer::valueOf). // -> on single
publishOn(Schedulers.parallel()). // -> on single
map(x -> x * x). // -> on parallel
subscribe(System.out::println) // -> on parallelThe flatMap case
Remember, when doing a flatMap, you return a Flux or Mono. This stream can have its own scheduler set. This scheduler won’t be overriden by any of the publishOn or subscribeOn method of the parent stream, but by default, it will run on the same scheduler as the parent.
This allow you to set different schedulers depending on what happens in your flatMap. For example, in case of error, you might want the Mono.error(...) to run on the same scheduler as the parent, but in case of success, to run on a different scheduler than the parent. This configuration is up to you.
Parallel Flux
Flux runs sequentially by default. To make a Flux parallel, there exists a .parallel() method in the class. This method returns an instance of ParallelFlux .
Conversely, it is possible to turn a parallel flux into a sequential flux with the method .sequential() .
ParallelFlux has no method subscribeOn or publishOn . Instead, it has a runOn(Scheduler scheduler) method that acts exactly as publishOn. By default, not calling runOn(...) will run the stream in the thread where you subscribed to it.
Combining Flux, Mono and ParallelFlux, by examples
For the following examples, I will very often use the following function:
private <T> T identityWithThreadLogging(T el, String operation) {
System.out.println(operation + " -- " + el + " -- " +
Thread.currentThread().getName());
return el;
}First example
flatMap without changing the scheduler:
@Test
public void flatMapWithoutChangingScheduler() {
Flux.range(1, 3).
map(n -> identityWithThreadLogging(n, "map1").
flatMap(n -> Mono.just(n).map(nn -> identityWithThreadLogging(nn, "mono")).
subscribeOn(Schedulers.parallel()).
subscribe(n -> {
this.identityWithThreadLogging(n, "subscribe");
System.out.println(n);
});
}

Second example
Same as above, but subscribing the Mono to another scheduler. So the Mono.just(n).map(this::identityWithThreadLogging) is suffixed with .subscribeOn(Schedulers.elastic()) . The new output is:


As you might have noticed, each Mono was executed on a different thread. which was not the case for without adding subscribeOn(...) to the Mono . This made a part of the execution of the Flux parallel. That would also have worked with the parallel scheduler on the monos.
Also, the subscription of the Flux itself runned on the scheduler configured on each Mono .
Third example
With the same basis as the above examples, let’s make things more complicated. The code will speak for itself:
@Test
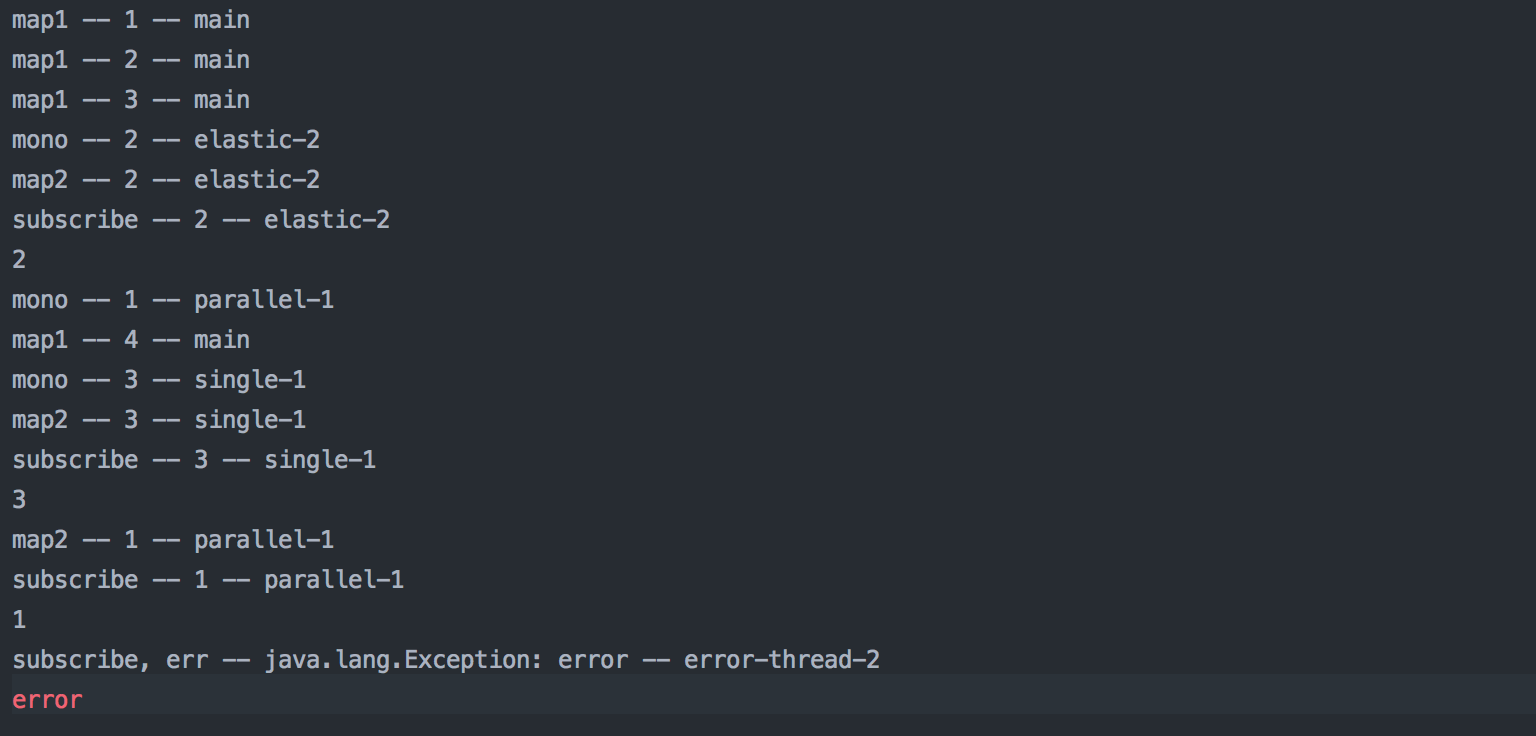
public void complexCase() {
Flux.range(1, 4).
subscribeOn(Schedulers.immediate()).
map(n -> identityWithThreadLogging(n, "map1")).
flatMap(n -> {
if (n == 1) return createMonoOnScheduler(n, Schedulers.parallel());
if (n == 2) return createMonoOnScheduler(n, Schedulers.elastic());
if (n == 3) return createMonoOnScheduler(n, Schedulers.single());
return Mono.error(new Exception("error")).subscribeOn(Schedulers.newSingle("error-thread"));
}).
map(n -> identityWithThreadLogging(n, "map2")).
subscribe(
success -> System.out.println(identityWithThreadLogging(success, "subscribe")),
error -> System.err.println(identityWithThreadLogging(error, "subscribe, err").getMessage())
);
}
Fourth example
In this fourth example, I want to run all the second map and the subscribe on a single thread. Any idea how to do that ?
The solution is to add a .publishOn(Schedulers.single()) right before the second map. The result is:


Fifth example
This example’s goal is to show you that when working with ParallelFlux, the position where you call .runOn(...) matters.
@Test
public void runOnMethodCallOnParallelFluxMatters() {
// FIRST TEST : .runOn(parallel) after the sleeping map
ParallelFlux<Integer> fluxAfter = Flux.range(1, 100).parallel().
map(Object::toString).
map(Integer::valueOf).
map(i -> {
try { Thread.sleep(12); }
catch(InterruptedException e) { e.printStackTrace(); }
System.out.println(Thread.currentThread().getName());
return i;
}).
runOn(elastic).
map(i -> i % 2 == 0 ? i : i + 10);
long afterSleepingResult = TestUtils.mesureParallelFluxOnScheduler(fluxAfter, elastic);
// SECOND TEST : .runOn(parallel) before the sleeping map
ParallelFlux<Integer> fluxBefore = Flux.range(1, 100).parallel().
map(Object::toString).
map(Integer::valueOf).
runOn(elastic).
map(i -> {
try { Thread.sleep(12); }
catch(InterruptedException e) { e.printStackTrace(); }
System.out.println(Thread.currentThread().getName());
return i;
}).
map(i -> i % 2 == 0 ? i : i + 10);
long beforeSleepingResult = TestUtils.mesureParallelFluxOnScheduler(fluxBefore, elastic);
System.out.println("After sleeping result in an execution of " + afterSleepingResult + "ms");
System.out.println("Before sleeping result in an execution of " + beforeSleepingResult + "ms");
/* ---
Running this method gave me the following results :
after = 1369ms
before = 156ms
*/
}Sixth example
Combining parallel and sequential flux.
@Test
public void combiningParallelAndSequentialFlux() {
Flux.range(1, 4).
subscribeOn(Schedulers.parallel()).
map(n -> identityWithThreadLogging(n, "map1")).
parallel().
runOn(Schedulers.elastic()).
map(n -> identityWithThreadLogging(n, "parallelFlux")).
sequential().
map(n -> identityWithThreadLogging(n, "map2")).
subscribe(n -> identityWithThreadLogging(n, "subscribe"));
}

What is interesting with this example is to observe that even though the sequential Flux subscribe on the elastic scheduler, it uses only one thread to perform this operation. On the opposite, the ParallelFlux uses 4 threads.
In addition to show how schedulers are used, it shows how ParallelFlux and Flux handle tasks, and that it is possible to control the execution of a Flux very precisely.
Conclusion
In this fourth example, we took a look at how to control the execution of the streams that Reactor offers, leveraging the possibilities offered by the methods subscribeOn , publishOn ,runOn and the very complex compositions that can be made using the flatMap method properly.
In the next article, we will take a look at a few benchmarks I made. They intend to help you pick the right scheduler depending on the kind of work your program is doing.




